En este post se asumirá que el lector tiene un conocimiento en superficies de Riemann y topología algebraica.
Definición: Un grupo Fuchsiano es un subgrupo discreto de  .
.
Observación: Aquellos que conocen el Teorema de Uniformización, probablemente tengan en mente el siguiente resultado. Una superficie de Riemann compacta de género mayor o igual a 2 proviene del cuociente del disco unitario con un subgrupo de isometrías del disco. Este subgrupo es isomorfo al grupo fundamental, y por lo tanto, en vista del isomorfismo excepcional  , concluimos que dicho grupo de isometrías es un grupo fuchsiano (o isomorfo a uno).
, concluimos que dicho grupo de isometrías es un grupo fuchsiano (o isomorfo a uno).
Primero intentaremos caracterizar a los grupos Fuchsianos, una forma se basa en el lema siguiente. De aquí en adelante denotaremos 
Lema:  es Fuchsiano si y solamente si él actua discontinuamente (todas las órbitas discretas) en
es Fuchsiano si y solamente si él actua discontinuamente (todas las órbitas discretas) en  .
.
Demostración:
El grupo actúa libre y transitivamente sobre el fibrado tangente unitario  (pensar en el espacio tangente de considerando direcciones unitarias, si fija un punto y una dirección, debe ser la identidad). Luego es discreto, si y solamente si, la acción en el fibrado es discreto. Así, las órbitas son discretas en si y solamente si lo son en .
(pensar en el espacio tangente de considerando direcciones unitarias, si fija un punto y una dirección, debe ser la identidad). Luego es discreto, si y solamente si, la acción en el fibrado es discreto. Así, las órbitas son discretas en si y solamente si lo son en .

Definición: Un polígono de es un subconjunto cerrado, convexo, con borde geodésico por tramos. Un lado es un segmento geodésico maximal en el borde y un vértice (definicion temporal) es un punto del borde definido por ser la intersección de dos lados. El polígono se dice finito si tiene un número finito de lados.
El objetivo de este post es enunciar (y dar una intuición antes de eso) el Teorema del Polígono de Dirichlet.
Definición: Un polígono 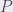 se dice fundamental para el grupo si las traslaciones de por el grupo cubren y las translaciones del interior del polígono son dos a dos disjuntas.
se dice fundamental para el grupo si las traslaciones de por el grupo cubren y las translaciones del interior del polígono son dos a dos disjuntas.
Definición: Un polígono de Dirichlet  asociado a y centrado en
asociado a y centrado en  es el conjunto
es el conjunto
 .
.
Con estas definiciones, es posible probar que para un grupo Fuchsiano y  de estabilizador trivial en , entonces el poligono de Dirichlet es un polígono (segun nuestra primera definición). Mas aún, dicho polígono es fundamental.
de estabilizador trivial en , entonces el poligono de Dirichlet es un polígono (segun nuestra primera definición). Mas aún, dicho polígono es fundamental.

Consideramos entonces un grupo Fuchsiano y un polígono de Dirichlet  centrado en un punto con estabilizador trivial. El objetivo de los siguientes parrafos es encontrar una representación del grupo.
centrado en un punto con estabilizador trivial. El objetivo de los siguientes parrafos es encontrar una representación del grupo.
Lema: Sea  . Entonces existe
. Entonces existe  tal que
tal que  pertenece también a
pertenece también a  . Además, un tal
. Además, un tal  es único si
es único si  no es un vértice.
no es un vértice.
Demostración:
Por la definición de polígono de Dirichlet, si y solamente si existe  tal que la distancia de a
tal que la distancia de a  (la orbita de ) es alcanzada por y
(la orbita de ) es alcanzada por y  . Así, la distancia de a es igual (recordar que la acción es por isometrías) a la distancia entre y
. Así, la distancia de a es igual (recordar que la acción es por isometrías) a la distancia entre y  , y por tanto nuestro elemento buscado es
, y por tanto nuestro elemento buscado es  . Recíprocamente, si y están en el borde del polígono, entonces es equidistante de y
. Recíprocamente, si y están en el borde del polígono, entonces es equidistante de y  .
.
Si existiera un  tal que
tal que  está en la frontera del polígono, entonces
está en la frontera del polígono, entonces  y luego, si
y luego, si  entonces esta en la intersección de los polígonos fundamentales
entonces esta en la intersección de los polígonos fundamentales  . Como los polígonos cubren a se tiene que debe ser un vértice.
. Como los polígonos cubren a se tiene que debe ser un vértice.
Naturalmente, el lema anterior no nos especifica si uno podría tener que  . La igualdad puede ser alcanzada por los vértices, pero también por los puntos medios de los segmentos geodésicos (deben pensar que no puede ser otro punto del segmento pues debe haber una acción por isometría). Definimos entonces los vértices del polígono como los vértices ya definidos unidos a los puntos medios de los segmentos que satisfacen la igualdad anterior (es decir, tienen estabilizador no trivial). Con esta nueva definición, un punto en el borde que no es un vértice, debe tener por imagen (vía el único elemento del grupo descrito como antes) un punto del borde del polígono en un segmento geodésico que no es el mismo al cual pertenece. Si enumeramos los lados
. La igualdad puede ser alcanzada por los vértices, pero también por los puntos medios de los segmentos geodésicos (deben pensar que no puede ser otro punto del segmento pues debe haber una acción por isometría). Definimos entonces los vértices del polígono como los vértices ya definidos unidos a los puntos medios de los segmentos que satisfacen la igualdad anterior (es decir, tienen estabilizador no trivial). Con esta nueva definición, un punto en el borde que no es un vértice, debe tener por imagen (vía el único elemento del grupo descrito como antes) un punto del borde del polígono en un segmento geodésico que no es el mismo al cual pertenece. Si enumeramos los lados  , estos son aquellos tales que para cada
, estos son aquellos tales que para cada  existe un único
existe un único  del grupo, y un único
del grupo, y un único  tal que
tal que  envia
envia  en
en  (y este invierte la orientación dada por la la usual como borde de un conjunto convexo).
(y este invierte la orientación dada por la la usual como borde de un conjunto convexo).
Lo anterior nos dice que un polígono con cantidad finita de lados, debe tener cardinalidad de lados par. Además, por unicidad, es claro que  . Escribimos
. Escribimos  a tal involución.
a tal involución.
Definición: El par  se conoce como apareamiento de lados para el polígono .
se conoce como apareamiento de lados para el polígono .
Proposición: Suponiendo que es finito, entonces es generado por los .
Demostración:
Sea  . Si es uno de los , entonces pertenece a una copia de vecina a . Si no, consideremos un camino de a que evita vértices y es transversal a los lados (de todas las traslaciones de en caso que las intersecte). Consideramos la sucesion finita
. Si es uno de los , entonces pertenece a una copia de vecina a . Si no, consideremos un camino de a que evita vértices y es transversal a los lados (de todas las traslaciones de en caso que las intersecte). Consideramos la sucesion finita  de lados tales que el camino los cruza. Cada uno de esos lados es la imagen de un unico lado
de lados tales que el camino los cruza. Cada uno de esos lados es la imagen de un unico lado  de . De esta forma, el vecino de a lo largo de es por construccion la traslacion
de . De esta forma, el vecino de a lo largo de es por construccion la traslacion  . No es dificil de ver que
. No es dificil de ver que  . Con esto se concluye que
. Con esto se concluye que  .
.
En la figura adjunta se muestra un diseño de lo que sucede (los cambios de notacion son evidentemente adecuables a nuestra escritura)

Por último, podemos definir una relación de equivalencia entre los vértices del polígono. Dos vértices se relacionan si existe un elemento del grupo que envía uno en otro. Llamamos ciclo elíptico a una clase de equivalencia. Además, un ciclo es determinado por una cantidad finita de vértices debido al cubrimiento de las traslaciones del polígono y la discretitud del grupo. Finalmente se define como ángulo de un ciclo a la suma de los ángulos del polígono en cada vértice del ciclo.
Definición: Denotamos  . Si escribimos
. Si escribimos  , entonces el ciclo de
, entonces el ciclo de  es
es  donde
donde  es el primer entero tal que
es el primer entero tal que  .
.
Proposición: El ángulo de un ciclo es de la forma  para
para  . En tal caso
. En tal caso  genera el estabilizador de y es de orden
genera el estabilizador de y es de orden  .
.
Demostración:
Por construcción fija , luego es de orden finito (por ser discreto). Cualquier elemento que fija debe ser una rotación en ángulo el ángulo del ciclo. Es fácil ver que tal el elemento debe ser de la forma  donde
donde  es un multiplo de .
es un multiplo de .
Si resumimos, partiendo de un grupo Fuchsiano y un polígono de Dirichlet asociado, encontramos un apareamiento de lados, una involución que describe el apareamiento. Cada vértice pertenece a un ciclo, con ángulo de ciclo dividiendo a  . Los elementos que relacionan los lados satisfacen
. Los elementos que relacionan los lados satisfacen  y
y  donde el ángulo de ciclo es .
donde el ángulo de ciclo es .
Con esto en mente, es natural preguntarse si existe algún tipo de recíproco. En efecto
Teorema (Polígono de Poincaré)
Sea un polígono compacto de lados  con un apareamiento tal que el ángulo de cada ciclo divide a . Entonces el grupo generado por los es Fuchsiano y de representación
con un apareamiento tal que el ángulo de cada ciclo divide a . Entonces el grupo generado por los es Fuchsiano y de representación
 .
.
Debemos hacer una observacion no menor. Este resultado es mucho mas general, para (por ejemplo) un polígono no compacto, el cual tiene vértices en la frontera del plano hiperbólico. Estos vértices se conocen como vértices en el infinito, y sus ciclos se llaman ciclos parabólicos (pues la isotropía en esos puntos son elementos parabólicos de ). ¡Es un resultado precioso!.
Para concluir con este post, mostraremos una pequeña aplicación de estos resultados
Grupos Fuchsianos y Superficies de Riemann
Sea un polígono de  lados, de área finita, con un apareamiento . Escribimos
lados, de área finita, con un apareamiento . Escribimos  la cantidad de ciclos elípticos y
la cantidad de ciclos elípticos y  la cantidad de ciclos parabólicos.
la cantidad de ciclos parabólicos.
Proposición: Si satisface las hipótesis del Teorema de Poincaré y es el grupo generado por los , entonces el cuociente de  por es una superficie de Riemann compacta de género
por es una superficie de Riemann compacta de género

Demostración:
Las cartas para los puntos en las traslaciones del interior del polígono se definen por la identidad para una vecindad suficientemente pequeña. En los vértices elípticos se definen por  donde representa el ángulo del ciclo, y en los vértices en el infinito debemos ser mas sutiles. Después de conjugar, supongamos que el vértice es
donde representa el ángulo del ciclo, y en los vértices en el infinito debemos ser mas sutiles. Después de conjugar, supongamos que el vértice es  y que el elemento parabólico definido por el ciclo es
y que el elemento parabólico definido por el ciclo es  . Entonces la función
. Entonces la función  define una carta local. La compacidad proviene del cubrimiento finito definido por estas cartas (o también se puede pensar que estamos compactificando la superficie
define una carta local. La compacidad proviene del cubrimiento finito definido por estas cartas (o también se puede pensar que estamos compactificando la superficie  ) y el cálculo del género resulta de trazar triángulos desde el centro del polígono a los vértices (mirado todo en el plano hiperbólico) y luego cuocientamos y usamos la característica de Euler. Modulo la acción la triangulación nos queda con triángulos,
) y el cálculo del género resulta de trazar triángulos desde el centro del polígono a los vértices (mirado todo en el plano hiperbólico) y luego cuocientamos y usamos la característica de Euler. Modulo la acción la triangulación nos queda con triángulos,  vértices y
vértices y  aristas. Es decir,
aristas. Es decir,  .
.
Bibliografía:
[Sai2011] _____, Uniformisation des surfaces de Riemann, ENS Éditions, 2011.

 un difeomorfismo de clase
un difeomorfismo de clase  definido en una variedad Riemanniana
definido en una variedad Riemanniana  . Sea
. Sea  una medida boreliana de probabilidad en
una medida boreliana de probabilidad en  . Entonces, para
. Entonces, para 
;
de













 y lo pensaremos como una columna consistente de una sola linea horizontal. La transformación en este nivel será definida como la aplicación identidad.
y lo pensaremos como una columna consistente de una sola linea horizontal. La transformación en este nivel será definida como la aplicación identidad. y
y  , los imaginaremos como una sola columna consistente en dos lineas horizontales, una sobre otra. Pensemos que cortamos la columna del paso uno en la mitad y colocamos la segunda mitad sobre la primera. Esta nueva columna esta dotada de una aplicación natural, la cual lleva un elemento de la primera línea en su valor correspondiente en la segunda, y la última linea es llevada en su valor correspondiente en la primera. Debemos imaginar que estamos intercambiando posiciones de intervalos de largo
, los imaginaremos como una sola columna consistente en dos lineas horizontales, una sobre otra. Pensemos que cortamos la columna del paso uno en la mitad y colocamos la segunda mitad sobre la primera. Esta nueva columna esta dotada de una aplicación natural, la cual lleva un elemento de la primera línea en su valor correspondiente en la segunda, y la última linea es llevada en su valor correspondiente en la primera. Debemos imaginar que estamos intercambiando posiciones de intervalos de largo  .
. ,
,  y la segunda consistiendo de los intervalos
y la segunda consistiendo de los intervalos  ,
,  . Colocamos la segunda columna sobre la primera, y obtenemos una nueva columna de ancho 1/4, y una aplicacion natural descrita como antes; es decir,
. Colocamos la segunda columna sobre la primera, y obtenemos una nueva columna de ancho 1/4, y una aplicacion natural descrita como antes; es decir,
 la aplicación inducida en el intervalo
la aplicación inducida en el intervalo  descrita en el n-ésimo paso, entonces podemos definir la aplicación
descrita en el n-ésimo paso, entonces podemos definir la aplicación  como el límite puntual de las aplicaciones
como el límite puntual de las aplicaciones  , entonces, para
, entonces, para 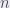 suficientemente grande,
suficientemente grande,  y por lo tanto
y por lo tanto  está bien definida por
está bien definida por  .
.

 . De esta forma, la medida de Lebesgue en el intervalo unitario permite hablar de una transformación que preserva la medida de Lebesgue. La aplicación
. De esta forma, la medida de Lebesgue en el intervalo unitario permite hablar de una transformación que preserva la medida de Lebesgue. La aplicación  deviene entonces en una transformación que preserva la medida de Lebesgue definida para todo punto del intervalo, salvo por un conjunto de medida nula (precisamente numerable). Formalmente obtenemos
deviene entonces en una transformación que preserva la medida de Lebesgue definida para todo punto del intervalo, salvo por un conjunto de medida nula (precisamente numerable). Formalmente obtenemos
 y
y  . Un cálculo sencillo nos dice que su entropía
. Un cálculo sencillo nos dice que su entropía  es igual a
es igual a  , por lo que la entropía de
, por lo que la entropía de  del tipo siguiente
del tipo siguiente dados por
dados por  , con
, con  ;
; tales que para
tales que para  ,
,  ;
; es
es  ;
; ,
,![g(x)\begin{cases} 1+x, & x\in[-2,0]\\ 1-x, & x\in[0,2]\\ \end{cases}](https://s0.wp.com/latex.php?latex=g%28x%29%5Cbegin%7Bcases%7D++++1%2Bx%2C+%26+x%5Cin%5B-2%2C0%5D%5C%5C++++1-x%2C+%26+x%5Cin%5B0%2C2%5D%5C%5C++++%5Cend%7Bcases%7D&bg=eeebf2&fg=3c3d47&s=0&c=20201002)
 para todo
para todo  .
. .
. lo es, y que por otra parte se tiene
lo es, y que por otra parte se tiene  , con
, con  . Luego, como
. Luego, como  arbitrario. Luego, escojamos
arbitrario. Luego, escojamos  , donde el signo escogido es tal que
, donde el signo escogido es tal que  y
y  están en el mismo segmento lineal de
están en el mismo segmento lineal de  .
. , para
, para  tenemos que:
tenemos que: , ya que
, ya que  para algún
para algún  tenemos que :
tenemos que : .
. estimamos,
estimamos,




 .
. se tiene que
se tiene que  , concluyendo así, que
, concluyendo así, que  una función continua tal que
una función continua tal que para todos
para todos 
 o
o  para algún
para algún  .
. o bien
o bien  , para mostrarlo es suficiente escribir
, para mostrarlo es suficiente escribir  lo que implica el resultado. Si
lo que implica el resultado. Si  para cada
para cada  , lo que implica que
, lo que implica que  pues para
pues para  por continuidad en el origen. Es fácil ver también que lo último implica que
por continuidad en el origen. Es fácil ver también que lo último implica que  para cada
para cada 
 ,
,  y
y  , de donde
, de donde

 .
. para cada
para cada  , entonces
, entonces .
. .
.
 ,
, , entonces
, entonces .
. y resolver la ecuación diferencial para concluir que
y resolver la ecuación diferencial para concluir que  continuas coinciden en un conjunto denso, entonces las funciones coinciden en toda la recta real. Para ello basta considerar un punto arbitrario y estudiar la convergencia a tal punto por sucesiones del conjunto denso, los límites deben ser iguales al evaluar en cada función. Finalmente, para cada
continuas coinciden en un conjunto denso, entonces las funciones coinciden en toda la recta real. Para ello basta considerar un punto arbitrario y estudiar la convergencia a tal punto por sucesiones del conjunto denso, los límites deben ser iguales al evaluar en cada función. Finalmente, para cada  , con
, con  , entonces
, entonces  . Es decir, para
. Es decir, para  y
y  coinciden sobre
coinciden sobre  . Nuestra primera observación en este párrafo concluye el resultado.
. Nuestra primera observación en este párrafo concluye el resultado. una propiedad aplicable sobre los números naturales y escribamos
una propiedad aplicable sobre los números naturales y escribamos  cuando el natural
cuando el natural  y
y  , entonces todos los números naturales satisfacen la propiedad
, entonces todos los números naturales satisfacen la propiedad  satisface una propiedad, basta considerar el dominó de naturales infinito truncado hasta la ficha
satisface una propiedad, basta considerar el dominó de naturales infinito truncado hasta la ficha  .
. , lo cual es trivial. La parte interesante (e insisto, la mas complicada lógicamente para muchos) es la segunda ley. Supongamos que un natural
, lo cual es trivial. La parte interesante (e insisto, la mas complicada lógicamente para muchos) es la segunda ley. Supongamos que un natural  también satisface la propiedad (debemos asegurar que la siguiente pieza de dominó caerá). Notemos entonces que
también satisface la propiedad (debemos asegurar que la siguiente pieza de dominó caerá). Notemos entonces que
 , por lo que
, por lo que
 .
. lo cual nos dice precisamente, si reemplazamos
lo cual nos dice precisamente, si reemplazamos  .
. tales que su suma es 180 grados (o mas comodamente,
tales que su suma es 180 grados (o mas comodamente,  radianes), entonces siempre existe un triángulo que contiene a tales ángulos, más aún, todas las isometrías de tal triángulo siguen satisfaciendo lo mismo, e incluso más aún, si dilatamos o contractamos el triángulo seguiremos obteniendo triángulos que tienen como componentes a los ángulos escogidos, a pesar de ya no ser isométricos entre si. Esto es algo que NO se satisface en geometría hiperbólica…
radianes), entonces siempre existe un triángulo que contiene a tales ángulos, más aún, todas las isometrías de tal triángulo siguen satisfaciendo lo mismo, e incluso más aún, si dilatamos o contractamos el triángulo seguiremos obteniendo triángulos que tienen como componentes a los ángulos escogidos, a pesar de ya no ser isométricos entre si. Esto es algo que NO se satisface en geometría hiperbólica…
 , de largos de lados
, de largos de lados  y ángulos
y ángulos  todos positivos. Vía una isometría es posible reducirnos al caso donde
todos positivos. Vía una isometría es posible reducirnos al caso donde  ,
,  ,
,  y
y  , esto es fácil de ver pues basta aplicar una isometría que lleve
, esto es fácil de ver pues basta aplicar una isometría que lleve  en
en  (la acción de
(la acción de  una rotación de centro
una rotación de centro  ,
,  el elemento hiperbólico de
el elemento hiperbólico de 


 , nos queda
, nos queda
 , de donde, si hacemos el cálculo e igualamos ciertos coeficientes de la matriz izquierda y derecha, se deducen las siguientes leyes
, de donde, si hacemos el cálculo e igualamos ciertos coeficientes de la matriz izquierda y derecha, se deducen las siguientes leyes


 , lo que implica que la suma de los ángulos de un triángulo en radianes es estrictamente menor que
, lo que implica que la suma de los ángulos de un triángulo en radianes es estrictamente menor que  . Sobre cada clase de homotopía libre existe una única geodésica de largo minimal. La existencia la entrega el teorema de Ascoli-Arzela y la unicidad proviene de usar el teorema de Uniformización, levantando dos curvas minimales al plano hiperbólico (geodésicas del plano hiperbólico pues la estructura de superficie de Riemann esta ligada a la métrica Riemanniana proveniente de la estructura hiperbólica) y llegar a una contradicción formando adecuadamente dos triángulos cuyas sumas de ángulos sea
. Sobre cada clase de homotopía libre existe una única geodésica de largo minimal. La existencia la entrega el teorema de Ascoli-Arzela y la unicidad proviene de usar el teorema de Uniformización, levantando dos curvas minimales al plano hiperbólico (geodésicas del plano hiperbólico pues la estructura de superficie de Riemann esta ligada a la métrica Riemanniana proveniente de la estructura hiperbólica) y llegar a una contradicción formando adecuadamente dos triángulos cuyas sumas de ángulos sea 
 .
. . Naturalmente, con lo que sabemos hasta ahora, visualizar esto no es evidente. Se hace necesario un modelo hiperbólico en el cual la geometría sea mucho más precisa y clarificante (pero pagando ese precio, perdemos facilidad en algunos cálculos).
. Naturalmente, con lo que sabemos hasta ahora, visualizar esto no es evidente. Se hace necesario un modelo hiperbólico en el cual la geometría sea mucho más precisa y clarificante (pero pagando ese precio, perdemos facilidad en algunos cálculos). , entonces la función
, entonces la función  , definida por
, definida por
 entonces
entonces  (ver figura), y por lo tanto
(ver figura), y por lo tanto  . Por otro lado, para
. Por otro lado, para  se tiene que
se tiene que  es un elemento del plano hiperbólico, y es el único elemento tal que al componerla con
es un elemento del plano hiperbólico, y es el único elemento tal que al componerla con  . Hemos encontrado una inversa continua.
. Hemos encontrado una inversa continua.
 dada por
dada por  , la cual de manera intuitiva representa la métrica imagen vía
, la cual de manera intuitiva representa la métrica imagen vía  (las distancias entre dos puntos del disco son las distancias de las imagenes vía
(las distancias entre dos puntos del disco son las distancias de las imagenes vía  .
. , por lo que una rotación con centro en «latex i» se traduce en el disco en una rotación con centro en el origen. Por otro lado, una rotación en ángulo
, por lo que una rotación con centro en «latex i» se traduce en el disco en una rotación con centro en el origen. Por otro lado, una rotación en ángulo  . Matricialmente esta acción está dada por
. Matricialmente esta acción está dada por
 de la forma
de la forma

 .
. es exactamente una rotación en ángulo
es exactamente una rotación en ángulo 
 y con distancia de desplazamiento
y con distancia de desplazamiento  .
. a
a  nos queda (como vimos en el post anterior) un elemento hiperbólico con punto repulsor
nos queda (como vimos en el post anterior) un elemento hiperbólico con punto repulsor  y atractor
y atractor 
 .
. actúa en
actúa en  y
y 


 (por lo que la acción está bien definida).
(por lo que la acción está bien definida). con cierta estructura que deja en evidencia una base (visto como espacio vectorial). Escogemos entonces una base para
con cierta estructura que deja en evidencia una base (visto como espacio vectorial). Escogemos entonces una base para  ,
,  y
y 
 , en la base anterior se escribe matricialmente como
, en la base anterior se escribe matricialmente como
 . Es posible verificar que
. Es posible verificar que  .
. , entonces
, entonces 
 , entonces
, entonces 
 , entonces
, entonces  .
.

 como las matrices cuadradas de
como las matrices cuadradas de  , a coeficientes reales y determinante 1. Definimos la acción de este grupo sobre el plano de Poincaré dado por las homografías, es decir;
, a coeficientes reales y determinante 1. Definimos la acción de este grupo sobre el plano de Poincaré dado por las homografías, es decir; .
. entonces
entonces .
. donde
donde  si y sólo si
si y sólo si  o
o  .
. a la acción de
a la acción de 

 (donde
(donde  representa la identidad en
representa la identidad en  es equivalente a resolver
es equivalente a resolver  .
. entonces la ecuación se transforma en
entonces la ecuación se transforma en  (y la ecuación siempre se satisface en infinito). Para
(y la ecuación siempre se satisface en infinito). Para  (notar que
(notar que  ) entonces
) entonces  . Además
. Además  , por lo que la ecuación tiene sólo una solución (o punto fijo) en
, por lo que la ecuación tiene sólo una solución (o punto fijo) en  si y solamente si
si y solamente si  .
.  entonces la ecuación se escribe como
entonces la ecuación se escribe como  y la cantidad de soluciones depende del discriminante. Notar que su discriminante es
y la cantidad de soluciones depende del discriminante. Notar que su discriminante es  . Si
. Si  entonces la ecuación tiene dos soluciones complejas conjugadas (una en
entonces la ecuación tiene dos soluciones complejas conjugadas (una en  entonces la solución es única y se encuentra en
entonces la solución es única y se encuentra en  . Decimos que
. Decimos que  en un grupo se dicen conjugados si existe
en un grupo se dicen conjugados si existe  otro elemento del grupo tal que
otro elemento del grupo tal que  . Por otra parte, sabemos que
. Por otra parte, sabemos que  . Resolviendo le ecuación del punto fijo nos queda
. Resolviendo le ecuación del punto fijo nos queda  por lo que
por lo que  y
y  . Como el determinante de la matriz es 1, entonces
. Como el determinante de la matriz es 1, entonces  . Con esto se concluye que existe
. Con esto se concluye que existe  tal que
tal que 

 y
y  . Luego es posible encontrar
. Luego es posible encontrar  tal que
tal que 
 podemos suponer
podemos suponer  . Recordemos también que, de acuerdo a la métrica Riemanniana sobre el plano hiperbólico, se tiene que
. Recordemos también que, de acuerdo a la métrica Riemanniana sobre el plano hiperbólico, se tiene que  por
por  por el eje imaginario. Como la acción es por isometrías, todo punto en el semiplano es trasladada a distancia
por el eje imaginario. Como la acción es por isometrías, todo punto en el semiplano es trasladada a distancia  como la distancia de desplazamiento de
como la distancia de desplazamiento de  .
. nos queda
nos queda
![p(z)\in\mathbb{C}[z]](https://s0.wp.com/latex.php?latex=p%28z%29%5Cin%5Cmathbb%7BC%7D%5Bz%5D&bg=eeebf2&fg=3c3d47&s=0&c=20201002) tal que todas sus raíces se encuentran en el semiplano superior
tal que todas sus raíces se encuentran en el semiplano superior  también están en este semiplano.
también están en este semiplano. y que las raices son
y que las raices son  (pudiendo éstas repetirse). Entonces
(pudiendo éstas repetirse). Entonces .
. nos queda
nos queda  por lo que
por lo que .
. es raiz de
es raiz de  esta bien definida en
esta bien definida en 
 , lo anterior se reduce a
, lo anterior se reduce a
 para todo
para todo  por lo que
por lo que  . Esta es una contradicción pues la suma de complejos con parte imaginaria estrictamente positiva no puede ser nula. Esta contradicción viene del suponer que una raíz de
. Esta es una contradicción pues la suma de complejos con parte imaginaria estrictamente positiva no puede ser nula. Esta contradicción viene del suponer que una raíz de 